Use this file to discover all available pages before exploring further.
In traditional software engineering, CI/CD is the heartbeat of development. You wouldn’t deploy code without passing tests. However, applying this discipline to Intelligent Agents requires a fundamental paradigm shift, since Code is Deterministic (Logic) but Agents are Probabilistic (Behavior). We are moving from verifying syntax to evaluating cognitionAgentScope’s Evaluation Module is designed to be the CI/CD pipeline for your Agents. It transforms the vague art of “prompt engineering” into a measurable engineering discipline, providing the infrastructure to quantify reliability, catch regressions, and validate performance before you ship.It serves three critical roles in your development lifecycle:
Capability
Can the agent solve the specific tasks (e.g., Coding, Math) it was designed for?
Stability
Does it perform consistently across multiple runs? (e.g., success rate over 10 trials)
Regression Detection
Does behavior change when you tweak the system prompt or switch from qwen2.5-max to qwen3-max?
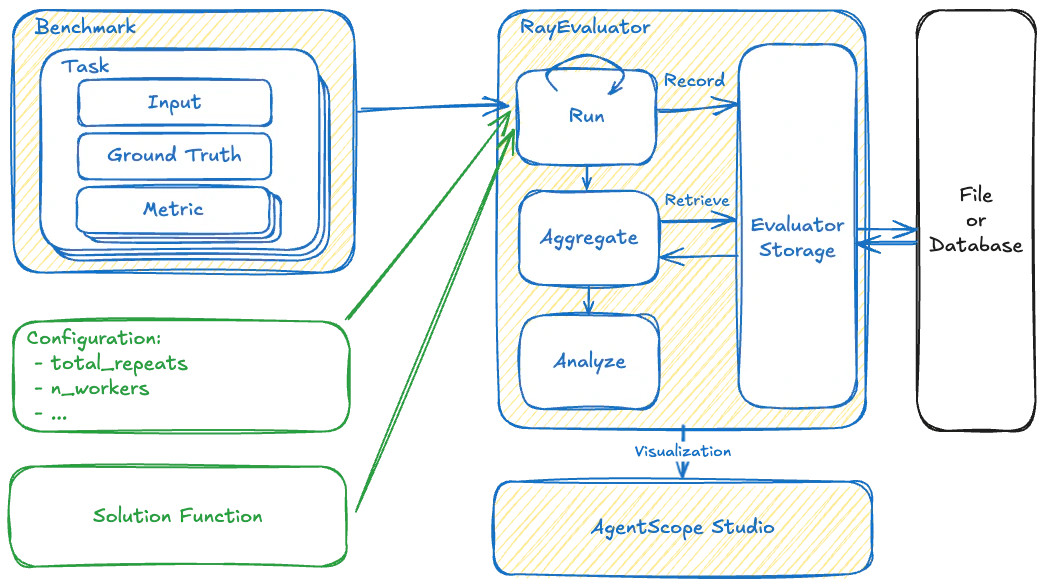
To address the complexity of evaluating agents, AgentScope employs a framework decomposes the evaluation into several key components:
Benchmark is responsible for defining “Task” (what to evaluate) and “Metric” (how to judge it). It is the static standard against which agents are measured.
Solution acts as an Adapter Pattern. Since every Agent might have unique input schemas or memory structures, the framework cannot call them directly. The Solution module standardizes this interaction.
Evaluator orchestrates the workflow. It manages resources, concurrency, and persistence. It serves as the bridge connecting the Benchmark to the Solution.
A Benchmark is not just a list of questions; it organizes multiple Tasks for systematic evaluation.
Crucially, the Task is the self-contained unit of evaluation that carries all information and Metric for the agent to execute and evaluate (e.g., input/query and its ground truth)
from agentscope.evaluate import Task, BenchmarkBase, MetricBase, MetricResult, MetricType, SolutionOutputclass MathBenchmark(BenchmarkBase): def __init__(self): super().__init__(name="MathBench", description="Basic Arithmetic Test") self.dataset = [ Task( id=item["id"], input=item["q"], ground_truth=item["a"], metrics=[CheckEqual(item["a"])] # Attach the judge to the question ) for item in TOY_BENCHMARK_DATA ] def __iter__(self): return iter(self.dataset) def __len__(self): return len(self.dataset) def __getitem__(self, index: int) -> Task: return self.dataset[index]
AgentScope includes standard benchmarks like ACEBench, a comprehensive multi-domain evaluation framework for testing AI agents’ tool usage and collaboration capabilities across diverse real-world scenarios — test against industry standards immediately.
The Solution is a function that acts as an Adapter. It takes a standardized Task as input and produces a standardized SolutionOutput.
This isolation ensures that you can swap agents without changing the benchmark, or swap benchmarks without rewriting the agent.
We need to define the logic for running agents and retrieving the execution result and trajectory in the Solution.
import osfrom typing import Callablefrom pydantic import BaseModelfrom agentscope.message import Msgfrom agentscope.model import DashScopeChatModelfrom agentscope.agent import ReActAgentfrom agentscope.evaluate import SolutionOutputclass AnswerFormat(BaseModel): answer_as_number: floatasync def math_agent_solution(task: Task, pre_hook: Callable) -> SolutionOutput: # 1. Initialize the Student (Agent) agent = ReActAgent( name="MathBot", sys_prompt="You are a calculator. Solve the problem.", model=DashScopeChatModel(model_name="qwen-max", api_key=os.getenv("DASHSCOPE_API_KEY")), ) # 2. Run the Test msg = Msg("user", task.input, role="user") res = await agent(msg, structured_model=AnswerFormat) # 3. Submit the Paper (Return SolutionOutput) return SolutionOutput( success=True, output=res.metadata.get("answer_as_number"), # Extract the specific answer trajectory=[] # We can capture the reasoning steps here )
Evaluators manage the evaluation process. They automatically iterate through tasks in the benchmark and feed each task into a solution-generation function.
import asynciofrom agentscope.evaluate import GeneralEvaluator, FileEvaluatorStorageasync def main(): evaluator = GeneralEvaluator( name="Math Evaluation Run", benchmark=MathBenchmark(), n_repeat=1, # Set to >1 to test stability storage=FileEvaluatorStorage(save_dir="./eval_results"), ) await evaluator.run(math_agent_solution)if __name__ == "__main__": asyncio.run(main())
AgentScope provides RayEvaluator, a drop-in replacement for GeneralEvaluator. It leverages the Ray framework to distribute tasks across available CPU/GPU workers, drastically reducing feedback time without requiring changes to your agent logic.An example using RayEvaluator with ACEBench multistep tasks is available in the GitHub repository.
While simple string matching (like the CheckEqual metric) works well for deterministic tasks, you can also implement MetricBase to use a stronger LLM to score subjective qualities such as tone, helpfulness, or safety, which are impossible to measure with simple code.To achieve this without building evaluation prompts from scratch, you can integrate OpenJudge. By connecting OpenJudge to AgentScope, you gain immediate access to 50+ battle-tested, professional-grade graders directly within the AgentScope MetricBase architecture.
To make OpenJudge compatible with AgentScope, we create an adapter class. This class inherits from MetricBase and translates AgentScope’s SolutionOutput into the payload OpenJudge expects.
from agentscope.evaluate import MetricBase, MetricResult, MetricType, SolutionOutputfrom openjudge.graders.base_grader import BaseGraderfrom openjudge.graders.schema import GraderScore, GraderErrorfrom openjudge.utils.mapping import parse_data_with_mapperclass OpenJudgeMetric(MetricBase): """ A wrapper that converts an OpenJudge grader into an AgentScope Metric. """ def __init__( self, grader_cls: type[BaseGrader], item: dict, mapper: dict | None = None, name: str | None = None, description: str | None = None, **grader_kwargs ): self.grader = grader_cls(**grader_kwargs) super().__init__( name=name or self.grader.name, metric_type=MetricType.NUMERICAL, description=description or self.grader.description ) self.item = item self.mapper = mapper or {} async def __call__(self, solution: SolutionOutput) -> MetricResult: if not solution.success: return MetricResult(name=self.name, result=0.0, message="Solution failed") try: # Combine Task Context (item) and Agent Output (solution) combined_data = { "item": self.item, "solution": solution.model_dump() } # Parse data using the mapper grader_inputs = parse_data_with_mapper(combined_data, self.mapper) result = await self.grader.aevaluate(**grader_inputs) if isinstance(result, GraderScore): return MetricResult(name=self.name, result=result.score, message=result.reason or "") elif isinstance(result, GraderError): return MetricResult(name=self.name, result=0.0, message=f"Error: {result.error}") else: return MetricResult(name=self.name, result=0.0, message="Unknown result type") except Exception as e: return MetricResult(name=self.name, result=0.0, message=f"Exception: {str(e)}")
Since the Task is the self-contained unit of evaluation that carries all information and metrics for the agent to execute and evaluate, we need to define a Mapper when constructing it. The mapper tells the wrapper how to extract the query, response, and context from your specific task data to feed into the OpenJudge Grader.
from agentscope.evaluate import Task, BenchmarkBasefrom openjudge.graders.common.relevance import RelevanceGraderimport osQA_DATA = [ { "id": "qa_task_1", "input": "What are the health benefits of regular exercise?", "reference_output": "Regular exercise improves cardiovascular health...", "ground_truth": "Answers should cover physical and mental health benefits" }]class QABenchmark(BenchmarkBase): def __init__(self): super().__init__(name="QA Benchmark", description="Advanced LLM-as-a-Judge Test") self.dataset = [] # Configure the judge model in OpenJudge (e.g., Qwen3-Max) model_config = { "model": "qwen3-max", "api_key": os.getenv("OPENAI_API_KEY") } for item in QA_DATA: # Map OpenJudge standard fields -> AgentScope paths mapper = { "query": "item.input", "response": "solution.output", "context": "item.ground_truth" } # Instantiate the OpenJudge Metric relevance_metric = OpenJudgeMetric( grader_cls=RelevanceGrader, item=item, mapper=mapper, name="Relevance", model=model_config ) # Attach the OpenJudge metric to the Task task = Task( id=item["id"], input=item["input"], ground_truth=item["ground_truth"], metrics=[relevance_metric] ) self.dataset.append(task) def __iter__(self): return iter(self.dataset) def __len__(self): return len(self.dataset) def __getitem__(self, index: int) -> Task: return self.dataset[index]
Once defined, this QABenchmark can be run seamlessly using the exact same GeneralEvaluator or RayEvaluator shown in the pipeline overview, standardizing your subjective assessments without changing the orchestrator logic.